
Earlier parts of this series covered the foundations of the company’s driver-assistance stack and how it interprets scenes. This installment focuses on how the system converts flat camera frames into the three-dimensional representation it uses to drive, drawing on two patent filings: Vision-Based Occupancy Determination and Vision-Based Surface Determination. Together, they describe how the stack perceives everything from vehicles to road texture using vision alone.
How FSD Works Part 1
How FSD Works Part 2
How FSD Works Part 3 (this article)
Tesla’s Universal AI Translator
How Tesla Optimizes FSD
How Tesla Will Label Data with AI

Creating a 3D World from 2D Images
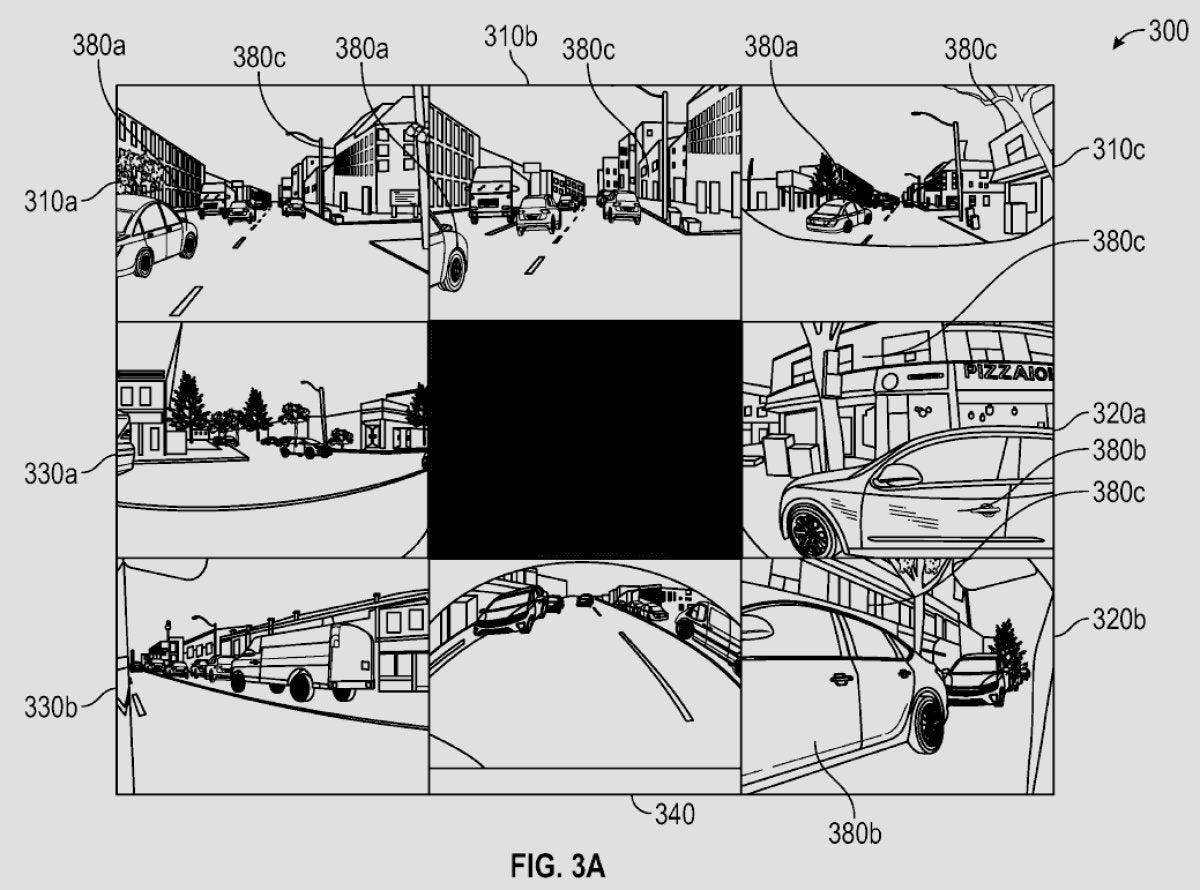
The core problem for a vision-based driver-assistance system is reconstructing a three-dimensional scene from two-dimensional camera inputs. Unlike approaches that use LiDAR to measure distance directly, a vision-only method must infer depth, shape, motion, and context from pixels, lighting, and how objects move across multiple camera perspectives. Combining these cues yields the 3D environment in which the planner operates.
Part 1: Vision-Based Occupancy Determination

The patent titled “Artificial Intelligence Modeling Techniques for Vision-Based Occupancy Determination” describes how the system identifies objects around the vehicle and the space they occupy. Earlier iterations used 2D bounding boxes; newer versions aim for a truly volumetric understanding.
FSD Pipeline: Pixels to Objects

The patent outlines a multi-stage AI pipeline:
Image input: Raw camera images from multiple viewpoints around the car are ingested at a given time.
Image featurization: Specialized neural networks called Featurizers extract useful visual features from pixels, such as patterns, textures, and edges.
Spatial transformation: A transformer network with a spatial attention mechanism projects features from each camera into a common 3D frame and fuses them. Internally, this forms the vector space in which the path planner operates.
Temporal alignment: The system fuses 3D features across consecutive moments so they become spatiotemporal, capturing not just an instant but motion over time.
Deconvolution: The fused representation is deconvolved to produce per-voxel predictions across a 3D grid.
A voxel is the 3D analogue of a pixel: a tiny cube representing a point in space. The environment around the car is discretized into a dense grid of voxels.
From the deconvolved outputs, the network predicts key signals such as occupancy (free or occupied) and, when occupied, a velocity vector. By aggregating across voxels, the system forms a detailed picture of nearby space and what fills it—whether a static structure or a moving road user.

The Output
The results are compiled into an occupancy map that downstream planning can query to decide next actions—checking whether specific regions are clear, whether an object in a voxel is moving, what it might be, and whether it matters for driving. The planner uses this continuously updated 3D model to make decisions moment to moment, much like navigating a live “video game”–style world where entities have location, motion, and type.
Part 2: Vision-Based Surface Determination
Detecting objects is only part of the problem; understanding the drivable surface and surrounding terrain is equally important. Patent WO2024237939A2, “Artificial Intelligence Modeling Techniques for Vision-Based Surface Determination,” addresses this need.
Surface Understanding
The system must infer far more than “there is a road.” It estimates road geometry (flat, uphill, banked), surface material (asphalt, dirt, gravel), curbs, lane markings, speed bumps, potholes, and whether a region is actually navigable. The patent explains how to reach this level of detail from cameras alone, reducing reliance on pre-existing high-definition maps.
For those watching closely, the system does attempt to identify potholes; whether the planner currently uses that signal can vary. Back in 2020, Elon confirmed this was the case.
Yes! We’re labeling bumps & potholes, so the car can slow down or steer around them when safe to do so.
— Elon Musk (@elonmusk) August 14, 2020
The company has also discussed adjusting air and adaptive suspensions based on a road roughness map. Such maps could combine outputs from Vision-Based Surface Determination with signals from new smart tire tread sensors now being installed on certain flagship vehicles.
Predicting Surface Attributes from Vision
This component analyzes images to predict surface attributes rather than object occupancy. Outputs include elevation, navigability and safety for driving, surface material, and features such as lane lines, markings, curbs, speed bumps, potholes, hill crests, and banked or flat curves.
Building the 3D Surface Mesh
These predictions are assembled into a 3D mesh of the surroundings derived from 2D imagery. The mesh is a set of points with X, Y, and Z coordinates, each tagged with the inferred attributes, forming part of the overall 3D world the system uses.

Training for Surface Recognition
Training leverages high-fidelity depth sources such as LIDAR during testing and data generation, as well as photogrammetry. These are aligned with camera images captured by real vehicles to learn distances and surface properties.
Occupancy + Surfaces = Unified World Model
The occupancy and surface systems are designed to work together. For example, if occupancy detects a traffic cone while the surface system recognizes a steep hill ahead, the model can place the cone accurately on the hill’s slope within the 3D world. Separating object detection from surface understanding improves robustness in environments with varying elevation and increases the vertical range in which objects can be localized reliably.
As a result, the stack does not just perceive isolated objects and a flat ground plane; it builds a semantically rich 3D understanding of what is around the vehicle and the attributes of that environment.
What Fuels FSD’s Decisions
This high-detail, real-time 3D world model—built from occupancy and surface estimates—feeds the subsequent stages of the stack: prediction (what other road users are likely to do), path planning (the safest and most efficient route), and control (executing the plan smoothly). You can read more about how those components are addressed in Part 1 of the series.
The path to full self-driving remains challenging, but these occupancy and surface methods are foundational building blocks for a system that not only detects patterns but also perceives and understands the dynamic, complex environments vehicles encounter.










































Partager:
Musk Drops Even More Hints About Tesla's New, Larger SUV
Tesla's Secret to the Cybertruck's Insane Turning Radius: 4-Wheel Steering Explained