
Le parti precedenti di questa serie hanno illustrato le fondamenta dello stack di assistenza alla guida dell’azienda e il modo in cui interpreta le scene. Questo episodio si concentra su come il sistema converte i fotogrammi piatti delle telecamere nella rappresentazione tridimensionale che usa per guidare, facendo leva su due brevetti: Vision-Based Occupancy Determination e Vision-Based Surface Determination. Insieme, descrivono come lo stack percepisce tutto, dai veicoli alla texture della strada, usando solo la visione.
Come funziona FSD Parte 1
Come funziona FSD Parte 2
Come funziona FSD Parte 3 (questo articolo)
Il traduttore universale di IA di Tesla
Come Tesla ottimizza FSD
Come Tesla etichetterà i dati con l’IA

Creare un mondo 3D da immagini 2D
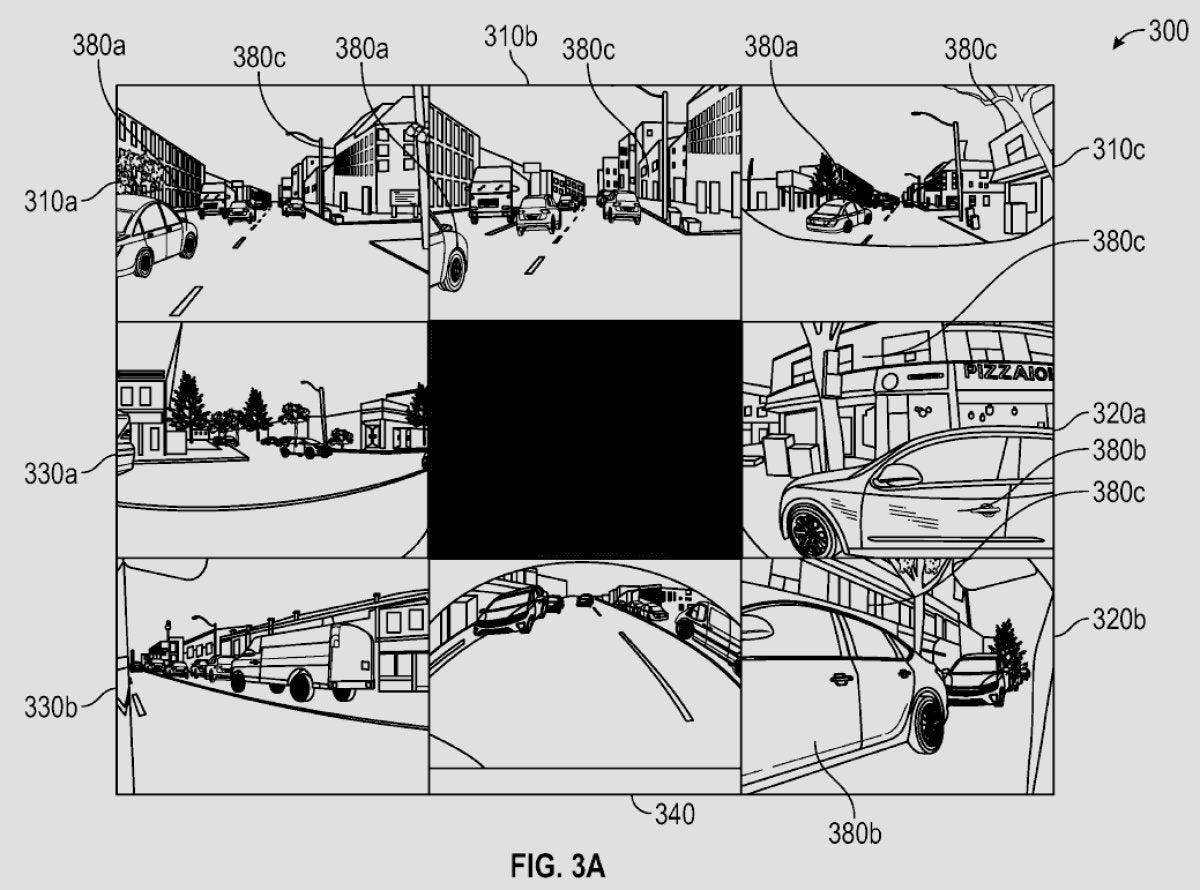
Il problema centrale per un sistema di assistenza alla guida basato sulla visione è ricostruire una scena tridimensionale a partire da input bidimensionali delle telecamere. A differenza degli approcci che usano il LiDAR per misurare direttamente la distanza, un metodo basato solo sulla visione deve dedurre profondità, forma, movimento e contesto da pixel, illuminazione e dal modo in cui gli oggetti si muovono tra più prospettive di telecamera. Combinando questi segnali si ottiene l’ambiente 3D in cui opera il pianificatore.
Parte 1: Determinazione dell’occupazione basata sulla visione

Il brevetto intitolato “Artificial Intelligence Modeling Techniques for Vision-Based Occupancy Determination” descrive come il sistema identifica gli oggetti attorno al veicolo e lo spazio che occupano. Le iterazioni precedenti usavano bounding box 2D; le versioni più recenti puntano a una comprensione davvero volumetrica.
Pipeline FSD: dai pixel agli oggetti

Il brevetto delinea una pipeline di IA in più fasi:
Input immagine: vengono acquisiti in un dato momento i fotogrammi grezzi delle telecamere da più punti di vista attorno all’auto.
Featurizzazione dell’immagine: reti neurali specializzate chiamate Featurizers estraggono dai pixel caratteristiche visive utili, come pattern, texture e bordi.
Trasformazione spaziale: una rete transformer con un meccanismo di attenzione spaziale proietta le feature di ciascuna telecamera in un frame 3D comune e le fonde. Internamente, questo costituisce lo spazio vettoriale in cui opera il pianificatore del percorso.
Allineamento temporale: il sistema fonde le feature 3D su momenti successivi, rendendole spazio-temporali e catturando non solo un istante ma anche il movimento nel tempo.
Deconvoluzione: la rappresentazione fusa viene deconvoluta per produrre previsioni per voxel su una griglia 3D.
Un voxel è l’analogo 3D di un pixel: un minuscolo cubo che rappresenta un punto nello spazio. L’ambiente attorno all’auto è discretizzato in una griglia densa di voxel.
Dalle uscite deconvolute, la rete prevede segnali chiave come l’occupazione (libero o occupato) e, quando occupato, un vettore di velocità. Aggregando i dati tra i voxel, il sistema costruisce un quadro dettagliato dello spazio vicino e di ciò che lo riempie, sia una struttura statica sia un utente della strada in movimento.

L’output
I risultati vengono aggregati in una mappa di occupazione che la pianificazione a valle può interrogare per decidere le azioni successive: verificare se regioni specifiche sono libere, se un oggetto in un voxel è in movimento, cosa potrebbe essere e se è rilevante per la guida. Il pianificatore usa questo Model 3D aggiornato continuamente per prendere decisioni momento per momento, un po' come navigare in un mondo in stile "videogioco" dal vivo in cui le entità hanno posizione, movimento e tipo.
Parte 2: Determinazione della superficie basata sulla visione
Rilevare gli oggetti è solo parte del problema; comprendere la superficie percorribile e il terreno circostante è altrettanto importante. Il brevetto WO2024237939A2, “Artificial Intelligence Modeling Techniques for Vision-Based Surface Determination”, risponde a questa esigenza.
Comprensione della superficie
Il sistema deve inferire molto più di “c’è una strada”. Stima la geometria della strada (piana, in salita, in contropendenza), il materiale della superficie (asfalto, terra, ghiaia), cordoli, linee di corsia, dossi, buche e se una zona sia davvero percorribile. Il brevetto spiega come raggiungere questo livello di dettaglio usando solo le telecamere, riducendo la dipendenza da mappe ad alta definizione preesistenti.
Per chi osserva con attenzione, il sistema prova effettivamente a identificare le buche; se il pianificatore usi o meno quel segnale può variare. Già nel 2020, Elon ha confermato che era così.
Sì! Stiamo etichettando dossi e buche, così l’auto può rallentare o aggirarli quando è sicuro farlo.
— Elon Musk (@elonmusk) 14 agosto 2020
L’azienda ha anche parlato di regolare sospensioni pneumatiche e sospensioni adattive in base a una mappa della rugosità stradale. Tali mappe potrebbero combinare gli output di Vision-Based Surface Determination con i segnali dei nuovi sensori smart sul battistrada degli pneumatici, ora installati su alcuni veicoli di punta.
Prevedere gli attributi della superficie dalla visione
Questo componente analizza le immagini per prevedere gli attributi della superficie anziché l’occupazione degli oggetti. Gli output includono quota, percorribilità e sicurezza per la guida, materiale della superficie e caratteristiche come linee di corsia, segnaletica, cordoli, dossi, buche, sommità delle salite e curve in contropendenza o piatte.
Costruire la mesh 3D della superficie
Queste previsioni vengono assemblate in una mesh 3D dell’ambiente circostante derivata da immagini 2D. La mesh è un insieme di punti con coordinate X, Y e Z, ciascuno contrassegnato dagli attributi inferiti, formando parte del mondo 3D complessivo che il sistema utilizza.

Addestramento per il riconoscimento della superficie
L’addestramento sfrutta fonti di profondità ad alta fedeltà come il LIDAR durante i test e la generazione dei dati, oltre alla fotogrammetria. Queste vengono allineate con le immagini delle telecamere catturate da veicoli reali per apprendere distanze e proprietà della superficie.
Occupazione + Superfici = Model unificato del mondo
I sistemi di occupazione e di superficie sono progettati per lavorare insieme. Per esempio, se l'occupazione rileva un cono stradale mentre il sistema di superficie riconosce una collina ripida più avanti, il Model può posizionare il cono con precisione sulla pendenza della collina all'interno del mondo 3D. Separare il rilevamento degli oggetti dalla comprensione della superficie migliora la robustezza in ambienti con elevazione variabile e aumenta l'intervallo verticale entro cui gli oggetti possono essere localizzati in modo affidabile.
Di conseguenza, lo stack non si limita a percepire oggetti isolati e un piano di appoggio piatto; costruisce una comprensione 3D semanticamente ricca di ciò che circonda il veicolo e degli attributi di quell’ambiente.
Cosa alimenta le decisioni di FSD
Questo Model del mondo 3D in tempo reale e ad alto livello di dettaglio, costruito a partire da stime di occupazione e superficie, alimenta le fasi successive dello stack: previsione (cosa probabilmente faranno gli altri utenti della strada), pianificazione del percorso (l'itinerario più sicuro ed efficiente) e controllo (esecuzione fluida del piano). Puoi leggere di più su come vengono affrontati questi componenti nella Parte 1 della serie.
La strada verso la guida completamente autonoma resta impegnativa, ma questi metodi di occupazione e superficie sono elementi fondamentali per un sistema che non solo rileva schemi, ma percepisce e comprende anche gli ambienti dinamici e complessi che i veicoli incontrano.
















Condividi:
Musk lascia ancora più indizi sul nuovo SUV Tesla più grande
Il segreto di Tesla per l'incredibile raggio di sterzata del Cybertruck: spiegazione dello sterzo a 4 ruote